7 MINUTE READ
Credit Agreement Analysis with CreditSeer
Enabling 50% faster, safer decisions by designing source-grounded extraction, AI guardrails, and failure-aware components
CONTEXT
CreditSeer is an AI-powered credit analysis tool built to help loan officers at regional banks and credit unions review syndicated loan agreements. Developed as part of Georgia Tech's Financial Services Innovation Lab, I led the product from early concept through to a working MVP that was tested with credit analysts across 15+ real credit agreements
TYPE
FinTech
B2B2C
Responsible AI
B2B2C
Responsible AI
ROLE
Product Designer (AI Systems)
DURATION
6 months
TEAM
Product Manager
2 ML Engineers
1 Frontend Developer
2 ML Engineers
1 Frontend Developer
PROBLEM
Credit analysts spend 2+ hours on credit agreement review....
Critical details are scattered
Reviewing credit agreements manually is slow because analysts must cross-reference key details scattered across hundreds of pages to understand a single credit facility.
....yet most LLMs aren't trustworthy enough for high-stakes decisions
Hallucinate values, creating regulatory risk
AI promises to solve the speed issue but a single extraction error can invalidate a financial recommendation and lead to regulatory failure.
Insight generation without transparency
Most LLMs prioritize "insight generation" (summarizing and interpreting), which lacks the transparency required for regulated finance. What loan officers actually need is defensible, auditable decision support, not an AI that tells them what to think.
SOLUTION
CreditSeer is an AI-assisted system that parses complex credit agreements into a structured, explainable dashboard, enabling faster review without sacrificing trust.
Reorganizing Complex Agreements Around Analyst Workflows
CreditSeer extracts high-value terms and restructures them around analyst questions, using the LLM for precise retrieval rather than interpretation or summarisation.
No False Insight Generation
Faster review
Low cognitive load
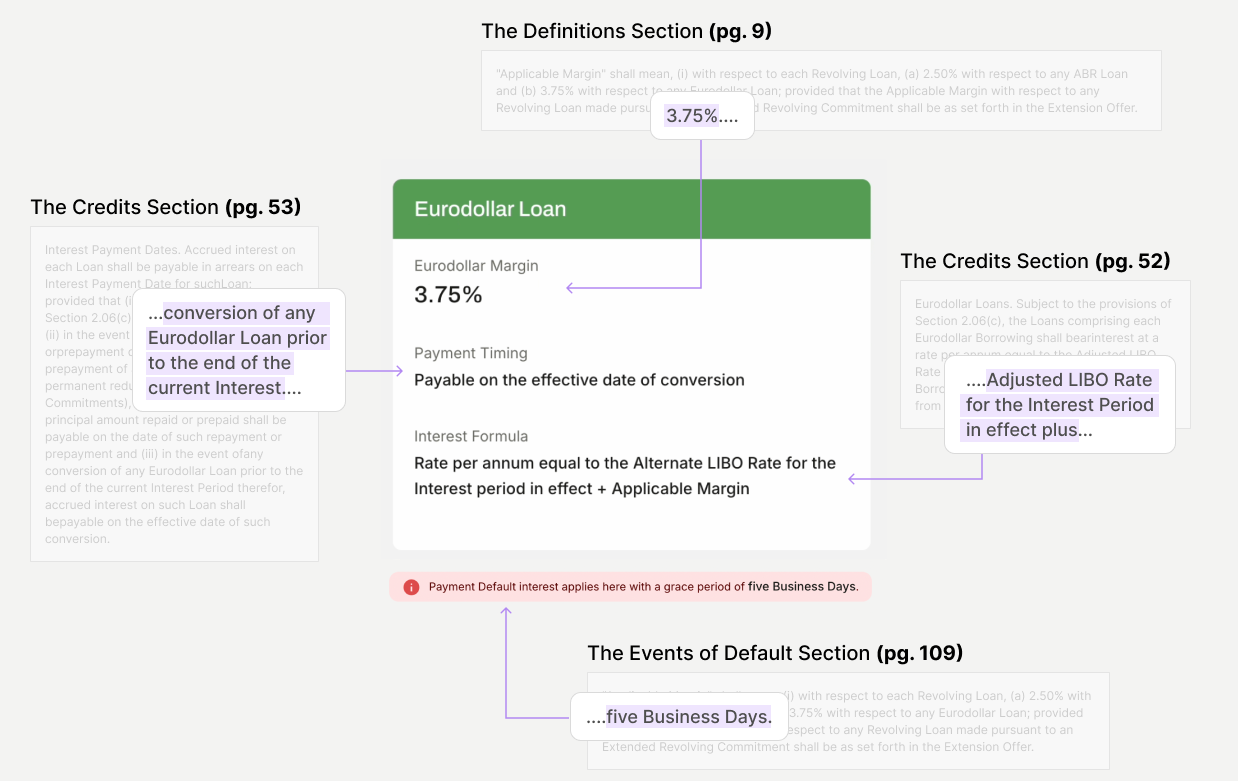
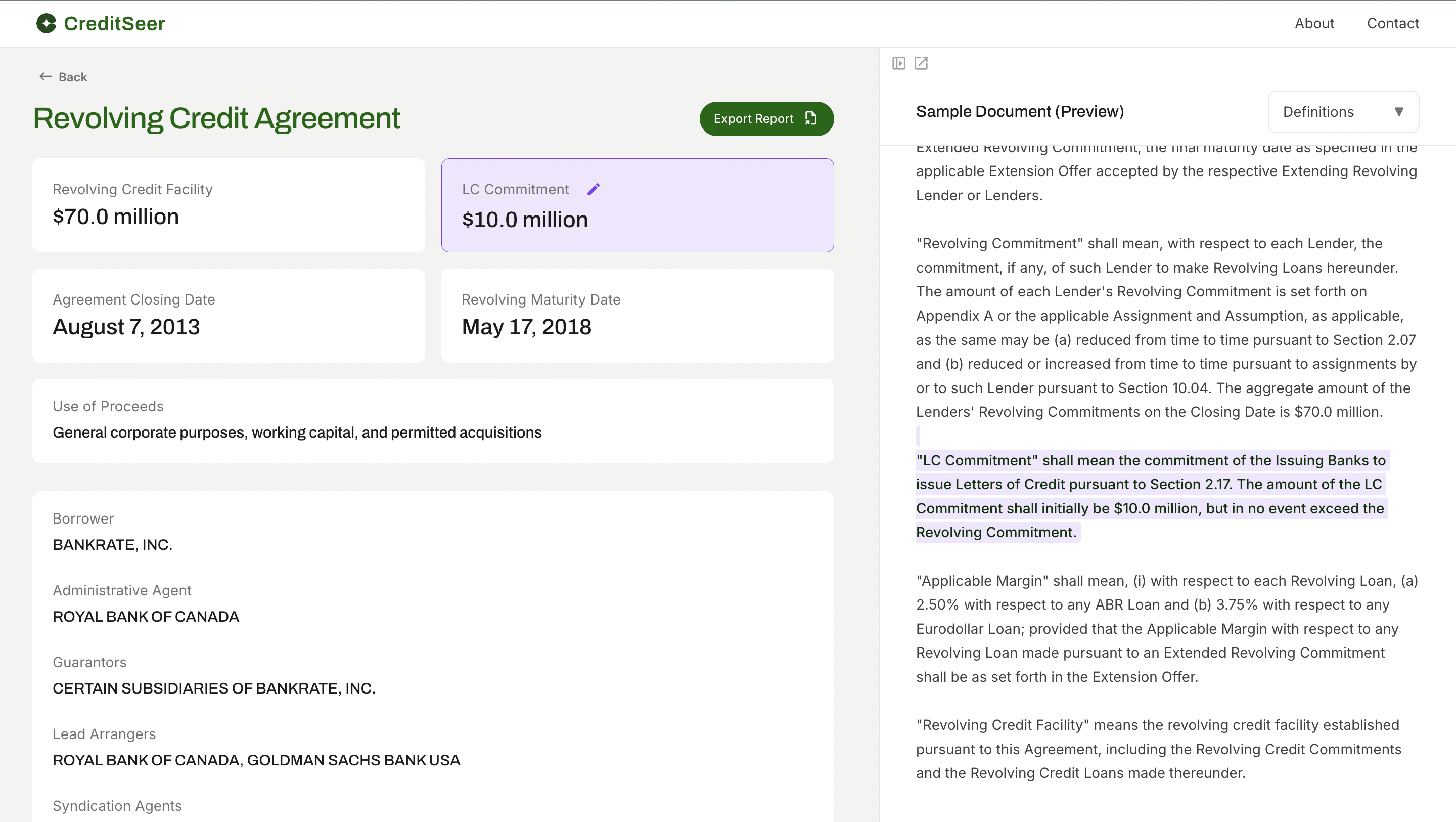
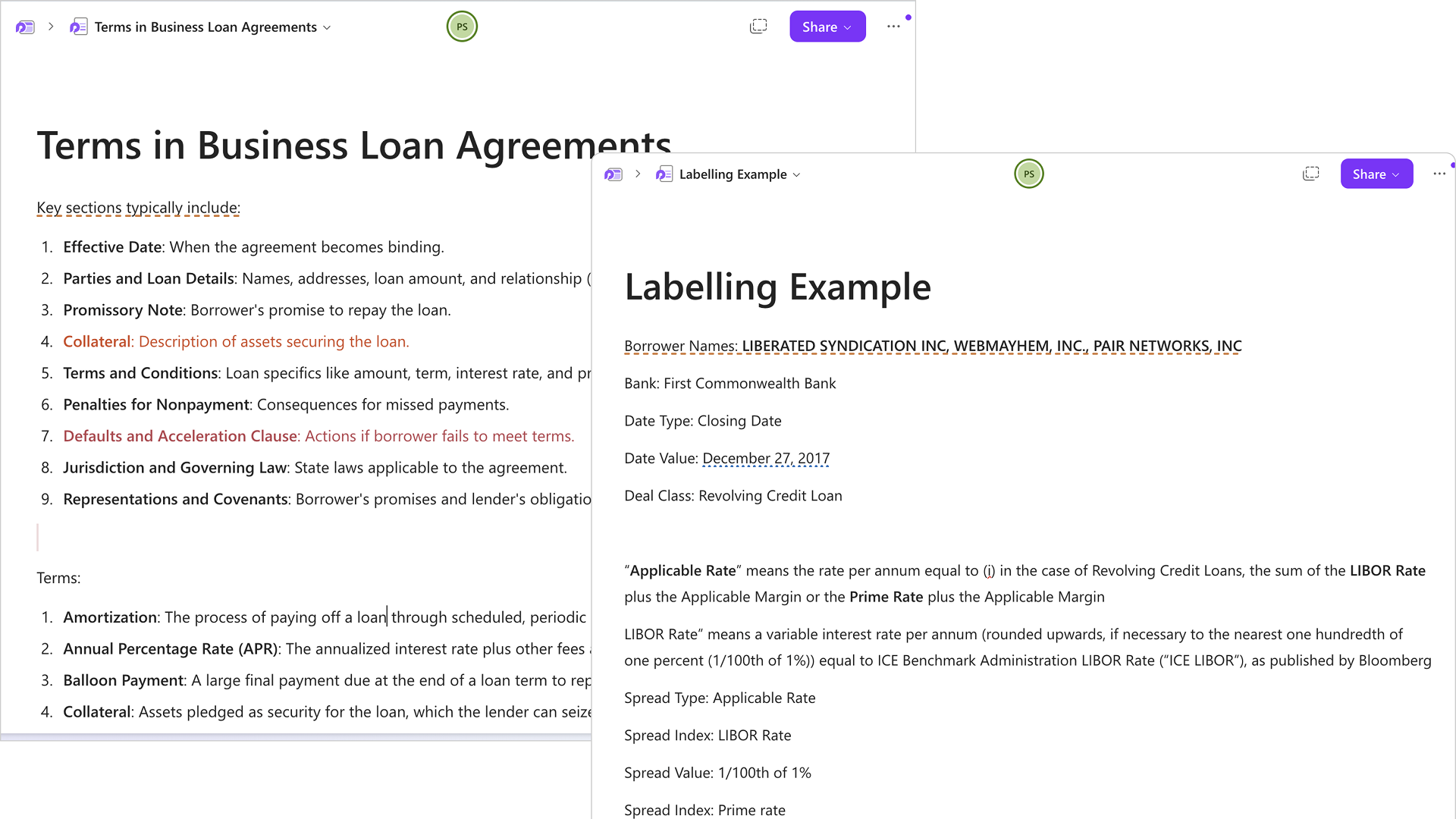
Making Every Extracted Value Explainable
Every extracted value is directly linked to its source clause and can be inspected with a single click. Analysts can verify accuracy in-context without manually searching through the agreement.
Instant verification
Auditable Decision Support
Trust through traceability
Degrading Gracefully When the Model Is Uncertain
The dashboard clearly surfaces ambiguous states and allows analysts to correct values, with each modification sending report for pipeline refinement, schema updates, and future annotation strategies.
Safe failure
Human-in-control
Continous model improvement loop
CONTEXT & CONSTRAINTS
When unreliable AI outputs broke the review experience, I realized the extraction system itself needed to be improved before the prototype could be tested with analysts.
In the earlier prototype, our model extracted structured values directly from large, article-level chunks
The prompt essentially asked: "Extract the base rate, applicable margin, commitment fee, and utilization fee."
The prompt essentially asked: "Extract the base rate, applicable margin, commitment fee, and utilization fee."
What Was Breaking the Product?
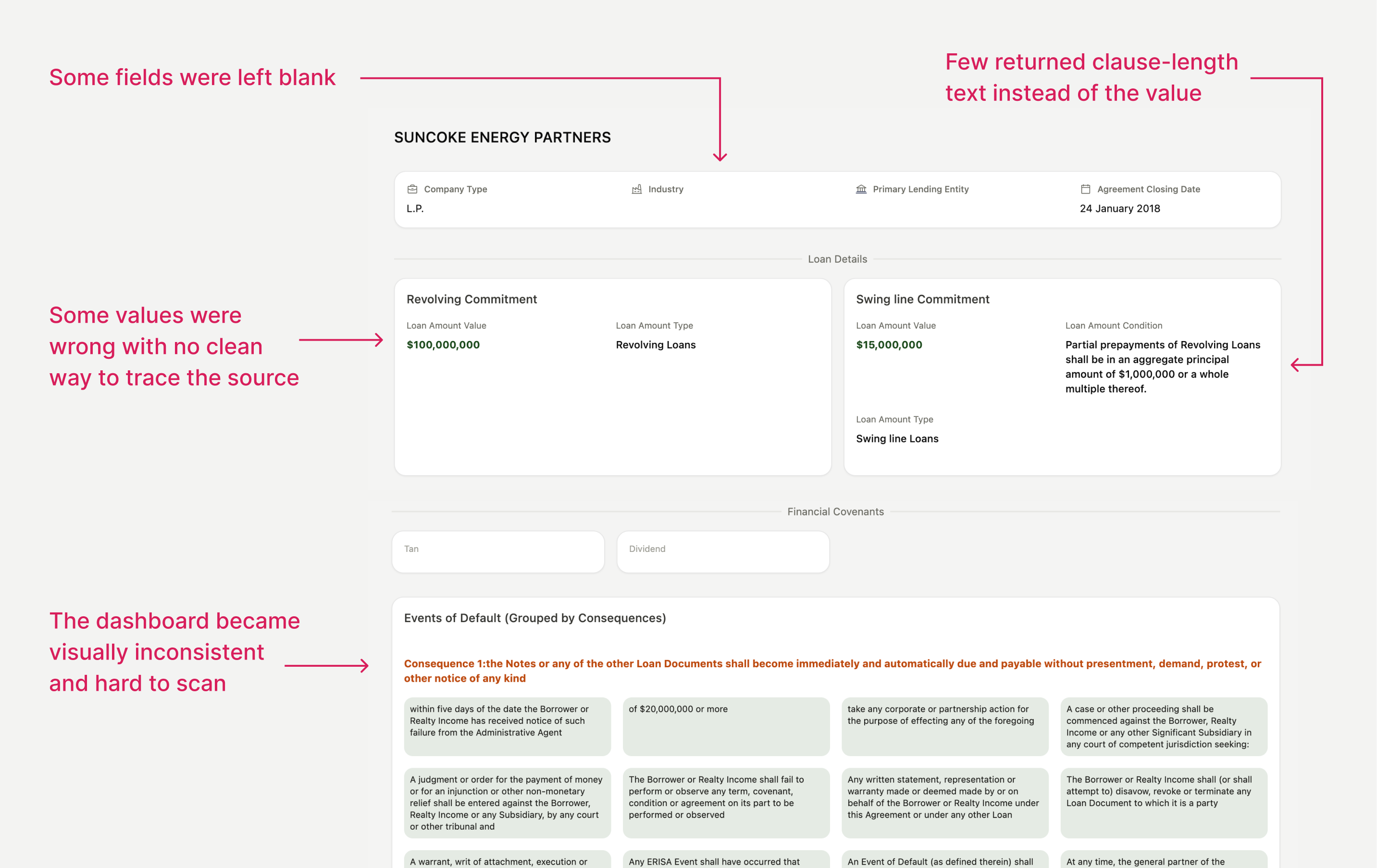
Why This Became a Product Problem (Not Just a Model Issue)
For the design:
Cards looked empty or visually messy, immediately eroding trust.
For workflow:
Analysts couldn’t get best of the dashboard or verify values efficiently.
For the system:
When outputs failed, there was no way to debug whether the issue came from.
I built the extraction pipeline first to understand what GenAI could reliably extract from credit agreements, then designed the interface around those technical constraints rather than idealized mockups—enabling analysts to evaluate real, testable outputs.
ALIGNING DESIGN, ML AND DOMAIN KNOWLEDGE
I worked closely with ML engineers to align what the system could extract with what analysts actually needed.
What did I do?
To avoid overbuilding or chasing unreliable fields, I analyzed 15+ real credit agreements and mapped (in json format)
-> what analysts consistently look for
-> where those values live across agreements
-> which fields were extractable with reasonable confidence
-> what analysts consistently look for
-> where those values live across agreements
-> which fields were extractable with reasonable confidence
Through multiple meetings with the ML engineers, I understood their model capabilities as well as identified edge cases and failure patterns early. I also documented financial concepts and agreement structures for shared understanding. This way I could also set realistic expectations with the stakeholders about MVP scope.
Impact?
For ML Team
Annotation schemas helped ML engineers decide feature set and boost their model accuracy
For Lab
My documentation helped support onboarding and alignment for people across teams.
SYSTEM ARCHITECTURE
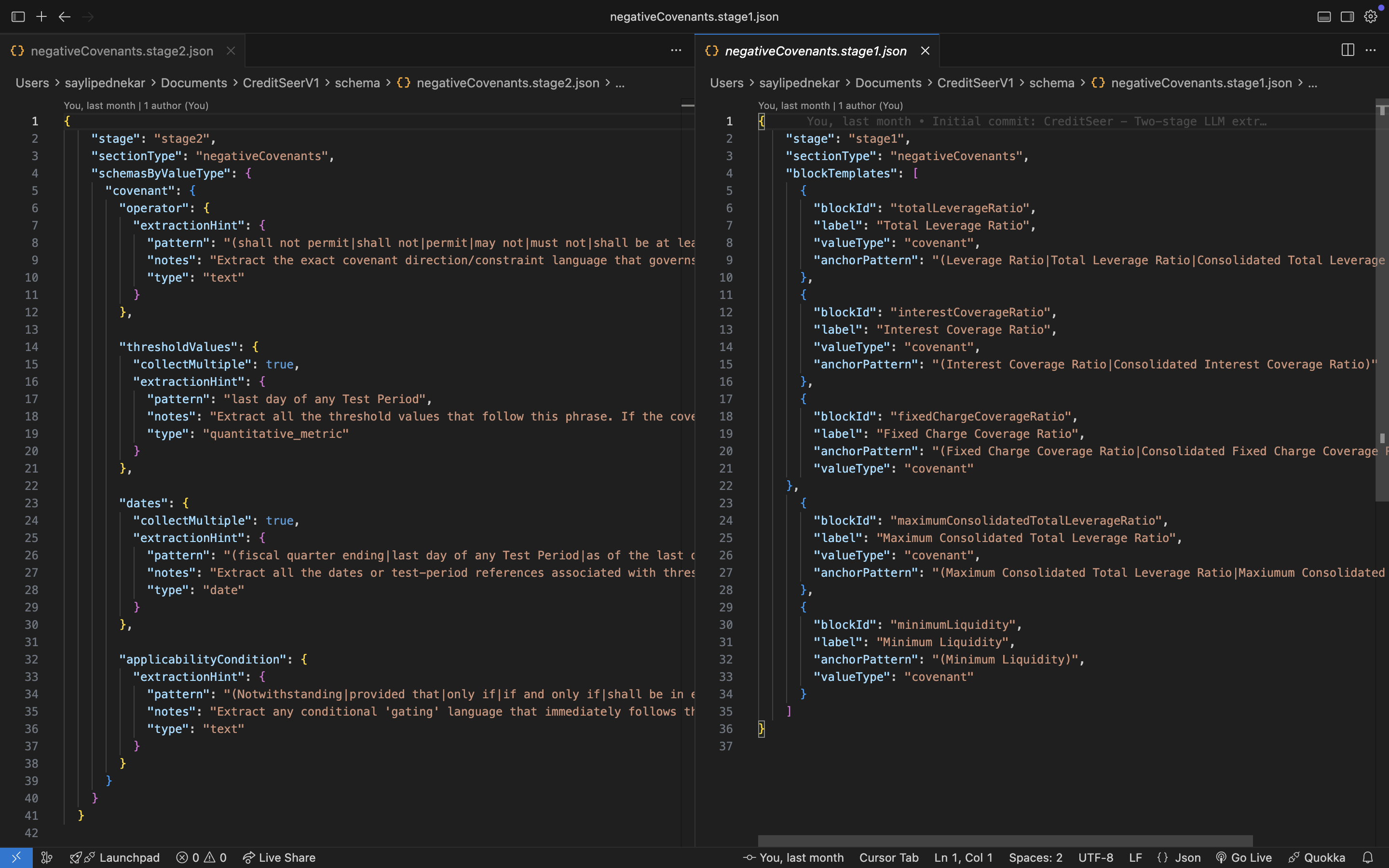
I came up with a two-stage extraction pipeline that made the system debuggable, designable, and trustworthy.
What did I do?
I redesigned the extraction logic into two focused steps with distinct goals:
Stage 1 — Block Discovery
Locate and return the most relevant clause verbatim using schema anchors, with section and page metadata.
Locate and return the most relevant clause verbatim using schema anchors, with section and page metadata.
Stage 2 — Value Extraction
Extract structured, UI-ready values from that block using strict schemas and ambiguity markers.
Extract structured, UI-ready values from that block using strict schemas and ambiguity markers.
Impact?
For the design:
UI components could now be designed with predictable data shapes, eliminating the "messy card" problem and enabling the consistent, scannable dashboard analysts needed.
For trust:
The two-stage approach made the model's reasoning visible, analysts could see both the extracted value AND the source block it came from, building confidence through transparency.
For debugging:
When something went wrong, the team could now isolate the issue was block discovery (Stage 1) or value parsing (Stage 2), dramatically speeding up iteration cycles.
For ML improvement:
The intermediate block artifacts created a natural annotation dataset. When analysts corrected values, we could trace back to see if the wrong block was retrieved or if parsing was the issue, directly informing model retraining priorities.
FRONTEND & IMPLEMENTATION
I built a functional React MVP and a design system that could handle AI uncertainty, not just the happy path.
What did I do?
Instead of relying on static mockups, I built the dashboard using Cursor.ai, Figma, and Vercel so analysts could play around with the MVP and give instand feedback.
I also created a design system which incorporated card components that handle variable AI outcomes
I also created a design system which incorporated card components that handle variable AI outcomes
Impact?
For the design:
Cut design–engineering feedback cycles from weeks to days, enabling rapid iteration based on real failure modes
For Lab
Created shared UI infrastructure reusable across the other projects in the lab
IMPACT
Analysts reached review readiness in roughly half the time, without skipping verification or relying on opaque AI summaries.
Through analyst walkthroughs and internal testing on 15+ real credit agreements,we compared time spent locating, cross-referencing, and verifying key terms manually vs.time spent reviewing the same terms in CreditSeer’s workflow-aligned dashboard
The largest time savings came from
-> eliminating manual cross-referencing across definitions, pricing, covenants, and defaults
-> surfacing only analyst-relevant terms in one structured view
-> enabling instant source verification instead of page-by-page searching
The largest time savings came from
-> eliminating manual cross-referencing across definitions, pricing, covenants, and defaults
-> surfacing only analyst-relevant terms in one structured view
-> enabling instant source verification instead of page-by-page searching
REFLECTION
AI Tools Pushed Me Beyond UX Into System Design
Using AI tools like Cursor helped me move beyond just designing screens. I ended up building parts of the extraction logic as well, which changed how I think about the role of a product designer—as someone who shapes system behavior, not just interfaces.
Understanding the Domain Was Necessary to Simplify It
To design for credit analysts, I had to deeply understand how syndicated credit agreements work. Learning the domain was key to turning dense, fragmented information into something usable and coherent.
Early Access to Users and Data Matters More Than Process
Working in fintech made it clear that limited access to real users and agreements can slow down the right decisions. In trust-critical domains, getting early exposure to real data and analyst workflows is essential to designing something reliable.
Designing for Uncertainty Is Part of Designing for AI
This project reinforced that AI won’t always be right, especially in high-stakes workflows. Making uncertainty visible and designing clear fallback paths helped keep the product usable and trustworthy.